
#1 sketch: Improve your IDE capabilities with documentation
This sketch proposes a simple solution to bring documentation right inside your IDE, thanks to MCP, Hugging Face and Gradio.


The frame
Generating some code with your IDE has become quite easy these days. You can question it, it performs research on the Internet, and you’re done. It’s almost the perfect assistant, and in a way you don’t even need to reach Google anymore.
However, so far I see a couple of limitations to this usage:
How do you augment your IDE with some specific documentation, or some that isn’t accessible publicly ?
How can you direct your IDE so that the search is not random on the Internet ?
For the sake of this sketch, let’s pretend that we want to have access to relevant documentation about CrewAI, in order to better understand the underlying concepts, and also generate a basic agent structure, as in the quickstart guide.
The mission
The rules of the game are as follow:
get a simple solution that may require some coding, but no infrastructure, databases, RAGs, etc.
find a solution totally free
get something that does the job simpler than scratching our head over writing fine-tuned prompts and instructions
The architecture
The architecture will have to be simple, and to keep things simple, I’ve decided to use what I consider the simplest way to extend the capabilities of my IDE: having an MCP server.
Now the trick is to use the simplest way to create and deploy a MCP server, and one of the easiest way I know is to code a MCP server with Gradio, and deploy it on a Hugging Face space. I’ll go with this then.
My MCP server will work this way in 2 rounds:
During round 1, the IDE will fetch the entire catalog (JSON format) from the MCP server, and decide on which documentation best matches the initial query
During round 2, the IDE has fetched the documentation ID that best matches the initial query, and calls the MCP server again to retrieve the content of the documentation
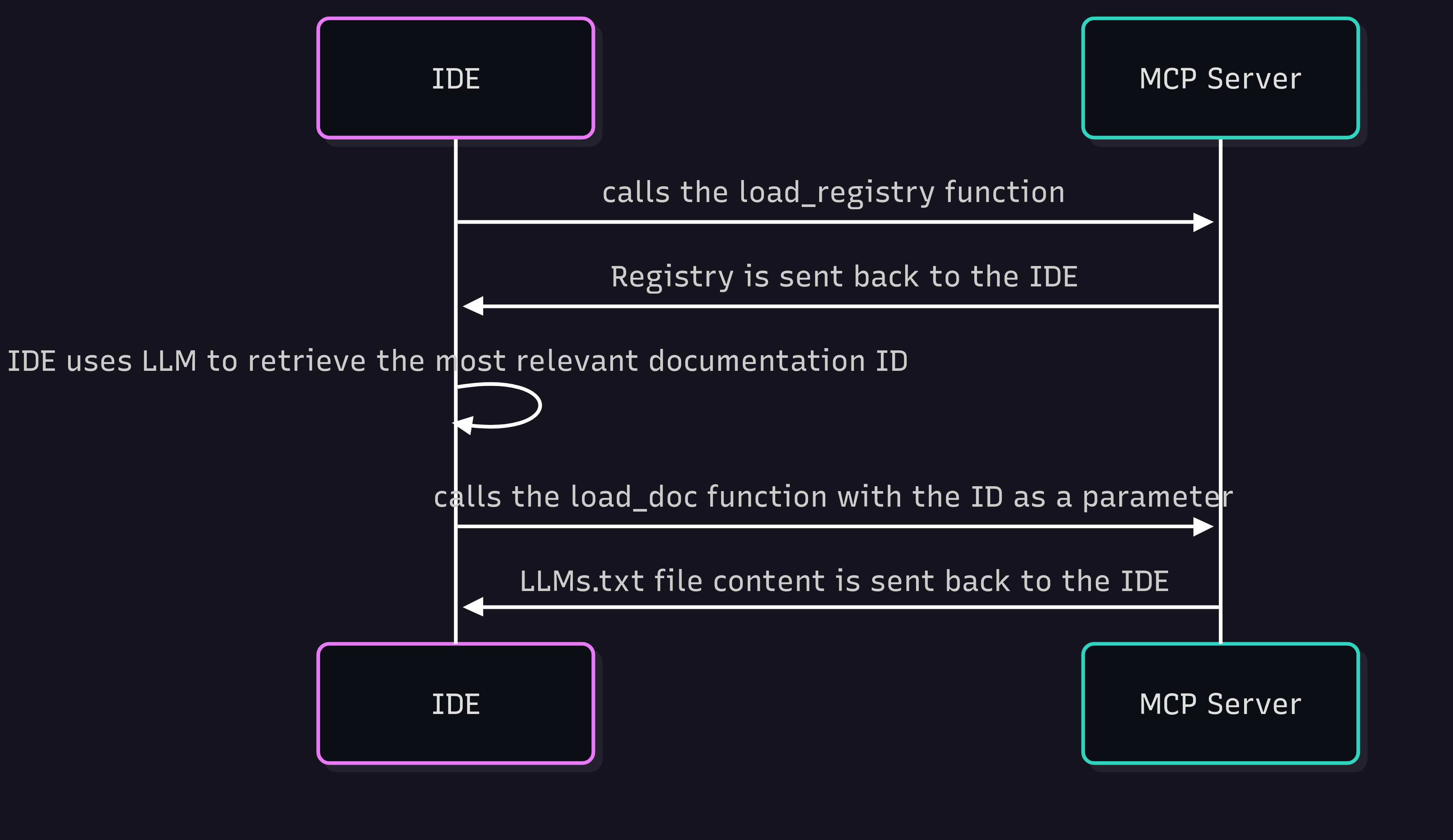
This is an extract of the documentation catalog that is retrieved by the IDE
id: the documentation id
description: the description of the documentation, this is the field that the IDE’s LLM will use to match the most relevant documentation to fetch
url: the documentation URL to crawl
Here is an extract of the documentation catalog, in JSON format.
[
{
"id": "langchain",
"description": "Open-source framework for developing applications using large language models with simplified tools and APIs.",
"url": "https://python.langchain.com/llms.txt"
},
{
"id": "langgraph",
"description": "Open-source framework from LangChain team for building complex stateful multi-agent applications using large language models.",
"url": "https://langchain-ai.github.io/langgraph/llms.txt"
},
{
"id": "anthropic",
"description": "API and services for Claude, an advanced AI assistant developed by Anthropic for various natural language processing tasks.",
"url": "https://docs.anthropic.com/llms.txt"
}
]You’ll notice that the documentation URL is always LLMs.txt format. These files are Markdown files, and their structure is optimal to be analyzed by a LLM. The framework’s editors also curated these files, which makes them particularly efficient in terms of information consistence. These markdown files also contain a lot of links to dig deeper into the intricacies of the framework’s understanding.
After round 2, it is the markdown documentation that is sent back to the IDE. The IDE will then work on this markdown file, crawl the links it contains if relevant regarding the initial request, and it will use this information to generate text or code.
The implementation
The implementation is quite simple. As you may have guessed, we’ll need two functions to operate the retrieval of the catalog, and the retrieval of a specific documentation.
def load_registry():
"""
This function (load_registry) should always be called first, before using the load_doc function. It will load the registry file and return the content of the registry. Based on that, you will then be able to pick and chose the documentation you want to load.
Returns:
str: The content of the registry, that contains the ID, a description and the URL location for each item of the registry, in JSON format
"""
try:
with open('llms.json', 'r') as file:
content = json.load(file)
return "```json\n" + json.dumps(content, indent=2) + "\n```"
except Exception as error:
print(f"Error reading llms.json: {error}")
return f"Error reading file: {str(error)}"The load_registry() function allows the retrieval of the catalog. It basically reads the JSON catalog file, and outputs it.
def load_doc(query):
"""
After getting the registry with the load_registry function, you can use this function to load the documentation you want to use.
Args:
query (str): The documentation ID you want to load
Returns:
str: The documentation content
"""
try:
# Read the llms.json file
with open('llms.json', 'r') as file:
content = json.load(file)
matching_entry = next((item for item in content if item['id'] == query), None)
if matching_entry is None:
return f"No documentation found for query: {query}"
url = matching_entry['url']
response = requests.get(url)
response.raise_for_status() # Raise an exception for bad status codes
return response.text
except FileNotFoundError:
return "Error: registry file not found"
except json.JSONDecodeError:
return "Error: Invalid JSON format in registry"
except requests.RequestException as e:
return f"Error fetching content from URL: {str(e)}"
except Exception as e:
return f"An unexpected error occurred: {str(e)}"The load_doc() function takes the documentation ID as a parameter and outputs the content of the matching URL.
The rest of the code is pretty straightforward, and revolves around shaping the application to benefit from a Gradio interface, and launch it. Note that when the Gradio server is launched, a mcp_server parameter is set to True. This is what makes the whole thing so cool: 1 parameter to transform your Gradio application into a MCP server !
with gr.Blocks(css=css) as demo:
gr.HTML("<center><h1>Documentation registry</h1></center>")
with gr.Row():
with gr.Column():
load_button = gr.Button("Load registry")
gr.HTML("<center><h2>OR</h2></center>")
query = gr.Textbox(label="Enter your registry ID")
search_button = gr.Button("Search documentation by ID")
with gr.Column():
output = gr.Markdown(elem_id="search_results")
load_button.click(load_registry, outputs=output)
search_button.click(load_doc, inputs=query, outputs=output)
if __name__ == "__main__":
demo.launch(mcp_server=True, strict_cors=False)You can access the whole code base here, feel free to use it and customize it to your own needs: https://huggingface.co/spaces/mysketches/llmstxt/tree/main
The deployment
Deployment is as easy as pushing some code in GitHub.
All you have to do is:
Create an account on Hugging Face
Create a space on Hugging Space
Init your space’s repository and push the code with git
And that’s it!
Now, go to your favorite IDE, and under the “MCP Tools” section, add these lines in the config JSON file
{
"mcpServers": {
"gradio": {
"url": "https://mysketches-llmstxt.hf.space/gradio_api/mcp/sse"
}
}
}Results
Thanks to this MCP Server, I could ask Cursor information about the notion of crews in CrewAI. It could fetch the catalog and give me information based on the official documentation of the framework.
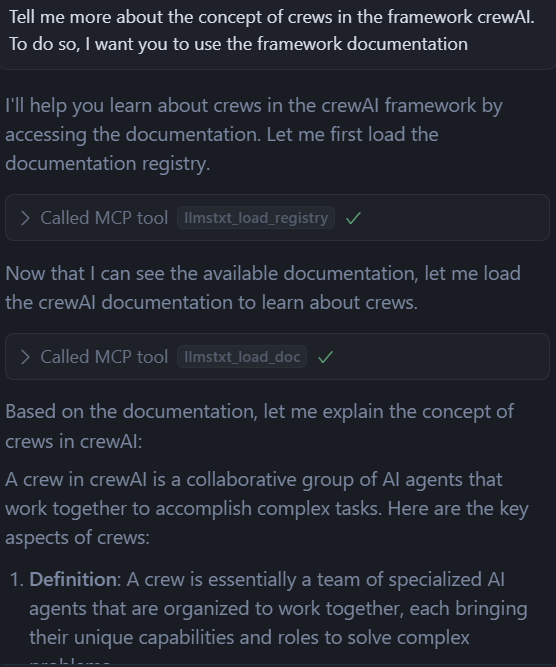
Therefore, I can say that this approach works.
There are subtleties, though. When I prompt something more complex, like generating some code, Cursor uses a mix of the information that it could find in the documentation, and the information it could gather on the Internet. Because Cursor is already augmented with Internet search capabilities, it will not consider the use of this MCP server mandatory. If needed, it can perform a search by himself.
I could counter this, though using a more imperative prompt, forcing Cursor to rely exclusively on the information it could find in the documentation, without searching in any other sources. In both cases (with/without Internet sources), the code could be generated, but many times the code could be generated without necessarily using the MCP Server.
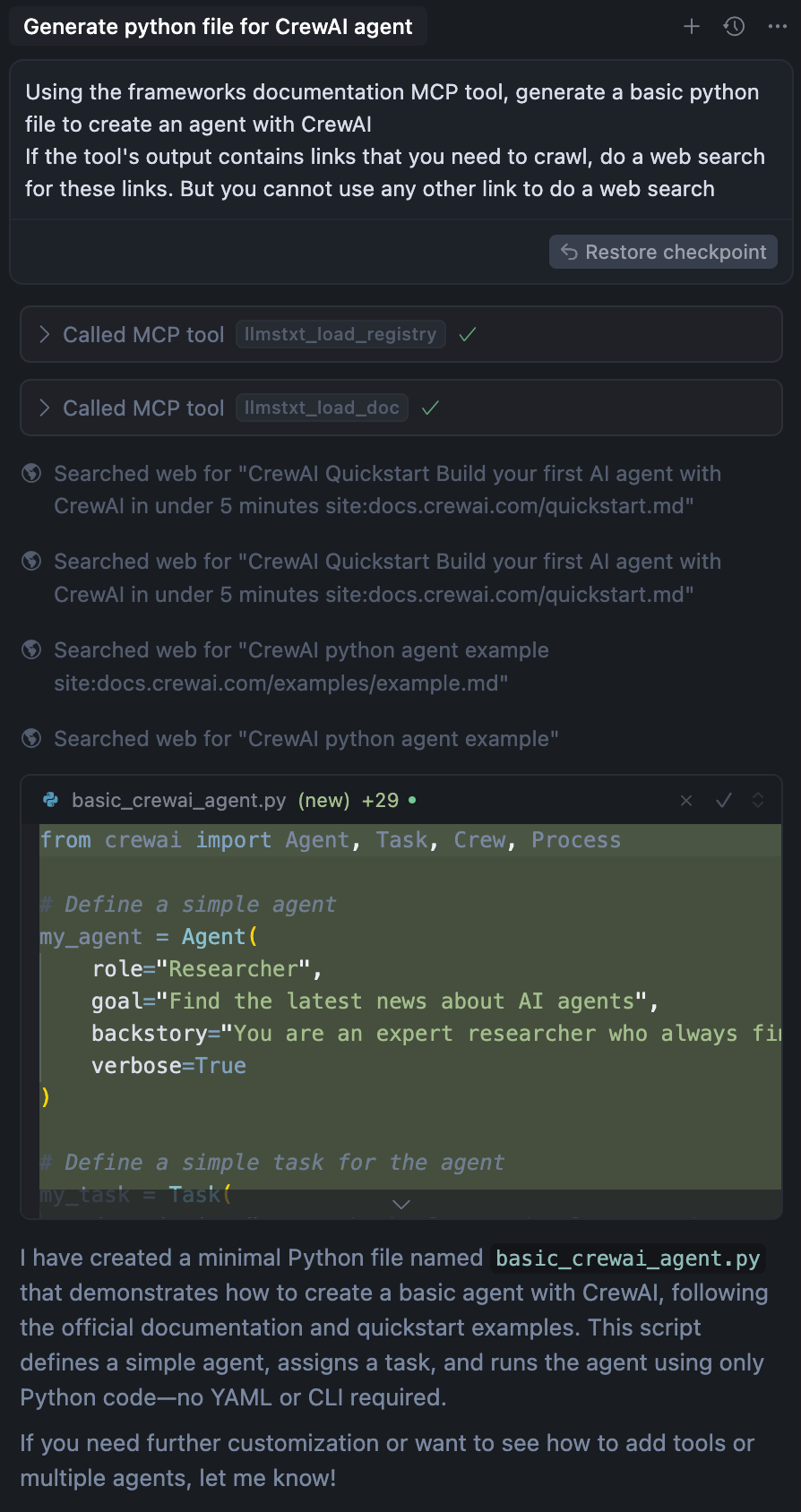
Finally, the greatest outcome is to have a visual interface for my MCP Server. The main advantage with Gradio is that it exposes an interface you can play with on Hugging Face space. The application is functional, and it is an awesome opportunity to visually test your MCP server before working in an automated way with and agent.
Integration of Gradio and Hugging Face was a real game changer. Although my use-case is quite trivial, I believe it could be worthwhile to dig deeper and see how far it can go regarding the functionalities you can onboard with your Gradio app.
Improvements
In this very simplistic architecture, the documentation catalog was integrated within the MCP Server. The major disadvantage of this approach was that it is not so easy to update the catalog as it was hard-coded within the MCP Server.
A first improvement would then be to rework the way data is stored in the catalog:
Use a database to store the catalog
Create a pipeline to update the catalog and add entries
The second thing to improve would deal with this 2 rounds approach. It is simpler to implement but not so simple to handle in the IDE. A cleverer approach would be to use a RAG to store the catalog. Using BigQuery could be interesting because it allows the indexation of embedded descriptions, and this would allow the MCP server to handle the whole request in 1 round, split into several steps:
embedding the query > find the semantic closest description > get the documentation URL > crawl it
The major advantage of this alternative approach would be to avoid relying on the IDE’s LLM to choose which documentation is the most relevant. By using a vector search on top of BigQuery, the MCP Server could handle the entire sequence on its own. This would foster a more fluent experience for the developer.
Conclusions
Augmenting your IDE with the ability to retrieve some documentation is achievable with little effort. However, I understand that the point is not so much about the feasibility, but about how to get the IDE to use the capability.
On the one hand, IDEs are already equipped with Internet search capabilities, which makes the use of external tools less obvious. On the other hand, I could check that Cursor would use all the capabilities available. Cursor could mix the use of the MCP server and Internet searches in order to get a more complete answer. This was quite unexpected, but is actually very smart, and fosters its chance to answer the prompt accurately.
In the end, is there a benefit in using a MCP server to allow an IDE to get more relevant documentation? Definitely.
Is the use of a MCP server mandatory to retrieve documentation ? Clearly not.
My final words are: “nice to have”, but not a game changer.